Referensi RAID (Redundant Array of Inexpensive Disks) Lengkap
RAID adalah kependekan dari Redundant Array of Independent Drive/Disk.
Ada juga yang menyebutnya sebagai kependekan dari Redundant Array of
Inexpensive Drive/Disk. Secara sedehana, RAID bisa diartikan sebagai
cara menyimpan data pada beberapa harddisk. Dengan begini, kinerja PC
bisa meningkat. Selain itu, salinan data juga bisa dijadikan back-up
Konsep RAID pertama kali didefinisikan pada tahun 1988, ketika sekelompok ilmuwan komputer di Universitas California Berkeley, (David Patterson, Garth Gibson, dan Randy Katz) menerbitkan makalah berjudul “A Kasus Redundant Array Inexpensive Disk (RAID)". Kebutuhan RAID dapat diringkas dalam dua poin di bawah ini. Dua kata kunci yang Redundant Array dan.
Dengan beberapa disk dan skema redundansi yang cocok, sistem anda dapat tetap up dan berjalan ketika sebuah disk gagal, dan bahkan ketika disk pengganti yang diinstal dan data dipulihkan.
Untuk membuat hemat biaya konfigurasi RAID yang optimal, kita perlu untuk secara bersamaan mencapai tujuan berikut:
2. cara di mana data yang berlebihan dihitung dan disimpan di array disk.
Data interleaving dapat berupa berbutir halus atau berbutir kasar.
Baik-baik saja array disk berbutir konseptual data yang interleave dalam unit relatif kecil sehingga semua I / O permintaan, terlepas dari ukuran mereka, mengakses semua disk dalam array disk. Hal ini menyebabkan kecepatan transfer data sangat tinggi untuk semua I / O permintaan namun memiliki kelemahan bahwa hanya satu logis I / O permintaan bisa dalam pelayanan pada waktu tertentu dan semua disk harus buang waktu positioning untuk setiap permintaan.
Array disk berbutir kasar interleave data dalam unit relatif besar sehingga saya kecil / O permintaan memerlukan akses hanya sejumlah kecil dari disk sementara permintaan besar dapat mengakses semua disk dalam array disk. Hal ini memungkinkan beberapa permintaan kecil untuk dilayani secara bersamaan sementara masih memungkinkan permintaan besar untuk melihat kecepatan transfer lebih tinggi diberikan dengan menggunakan beberapa disk.
Redundansi
Sejak jumlah yang lebih besar dari disk menurunkan keandalan
keseluruhan dari array disk, penting untuk memasukkan redundansi dalam
array disk untuk mentolerir kegagalan disk dan memungkinkan untuk terus
beroperasi dari sistem tanpa kehilangan data.
Penggabungan redundansi dalam array disk membawa dua masalah:
1. Memilih metode untuk menghitung informasi yang berlebihan. Kebanyakan berlebihan disk array saat ini menggunakan paritas, meskipun beberapa menggunakan kode Hamming atau Reed-Solomon.
2. Memilih metode untuk distribusi informasi yang berlebihan di seluruh array disk. Metode distribusi dapat diklasifikasikan menjadi 2 skema yang berbeda:
Ada banyak jenis RAID dan beberapa yang penting diperkenalkan di bawah ini:
Gangguan sistem
Sistem crash
mengacu pada setiap peristiwa seperti kegagalan daya, kesalahan
operator, perangkat keras kerusakan, atau crash perangkat lunak yang
dapat mengganggu operasi I / O untuk sebuah array disk.
Crash tersebut dapat mengganggu operasi menulis, sehingga negara-negara di mana data diperbarui dan paritas tidak diperbarui atau sebaliknya. Dalam kedua kasus, paritas tidak konsisten dan tidak dapat digunakan dalam hal kegagalan disk. Teknik seperti hardware dan pasokan listrik berlebihan dapat diterapkan untuk membuat crash tersebut kurang sering.
Crash sistem dapat menyebabkan inkonsistensi paritas di kedua array disk bit-interleaved dan blok-interleaved, tapi masalahnya adalah perhatian praktis hanya dalam array disk blok-interleaved.
Sebab, tujuan kehandalan, sistem crash di array disk blok-interleaved mirip dengan kegagalan disk dalam bahwa mereka dapat mengakibatkan hilangnya paritas benar untuk garis-garis yang diubah selama kecelakaan itu.
Uncorrectable bit-kesalahan
Paling uncorrectable bit-kesalahan yang dihasilkan karena data tidak benar tertulis atau secara bertahap rusak sebagai media magnetik usia. Kesalahan ini terdeteksi hanya ketika kita mencoba untuk membaca data.
Penafsiran kita tentang tingkat kesalahan bit uncorrectable adalah bahwa mereka mewakili tingkat di mana kesalahan yang terdeteksi selama membaca dari disk selama operasi normal dari disk drive.
Salah satu pendekatan yang dapat digunakan dengan atau tanpa redundansi adalah mencoba untuk melindungi terhadap kesalahan bit dengan memprediksi ketika disk akan gagal. VAXsimPLUS, produk dari Desember, memonitor peringatan yang dikeluarkan oleh disk dan memberitahu operator ketika merasa disk akan gagal.
Kegagalan disk berkorelasi
Penyebab: faktor lingkungan dan manufaktur umum.
Misalnya, kecelakaan mungkin tajam meningkatkan tingkat kegagalan untuk semua disk dalam array disk untuk waktu singkat. Secara umum, lonjakan daya, gangguan listrik dan hanya beralih disk dan mematikan dapat menempatkan tekanan pada komponen listrik dari semua disk yang terkena dampak. Disk juga berbagi umum hardware dukungan; ketika perangkat ini gagal, dapat menyebabkan beberapa, kegagalan disk simultan.
Disk umumnya lebih cenderung gagal baik sangat awal atau sangat terlambat dalam hidup mereka.
Kegagalan awal sering disebabkan oleh cacat sementara yang mungkin belum terdeteksi selama burn-in proses pabrikan.
Kegagalan akhir terjadi ketika disk habis dipakai. Kegagalan disk berkorelasi sangat mengurangi keandalan disk array dengan membuatnya lebih mungkin bahwa kegagalan disk awal akan diikuti oleh kegagalan disk tambahan sebelum disk gagal dapat direkonstruksi.
Mean-Time-To-Data-Rugi (MTTDL)
Berikut ini adalah beberapa rumus untuk menghitung rata-rata-waktu-data kerugian ( MTTDL ).
Dalam sebuah array disk paritas yang dilindungi blok-interleaved,
kehilangan data dimungkinkan melalui berikut tiga cara yang umum:
p (disk) = Probabilitas membaca semua sektor pada disk (berasal dari ukuran disk, ukuran sektor, dan BER)
Ada tiga pertimbangan penting saat membuat pilihan untuk yang tingkat RAID yang akan digunakan untuk sistem yaitu. biaya, kinerja dan kehandalan.
Ada banyak cara yang berbeda untuk mengukur parameter ini untuk misalnya. Kinerja dapat diukur sebagai I / Os per detik per dolar, byte per detik atau waktu respon. Kita juga bisa membandingkan sistem dengan biaya yang sama, kapasitas yang sama jumlah pengguna, kinerja yang sama atau keandalan yang sama. Metode yang digunakan sangat tergantung pada aplikasi dan alasan untuk membandingkan. Misalnya, dalam aplikasi pemrosesan transaksi basis utama untuk perbandingan akan I / Os per detik per dolar sedangkan pada aplikasi ilmiah kita akan lebih tertarik pada byte per detik per dolar. Dalam beberapa sistem heterogen seperti file server baik I / O per detik dan byte per detik mungkin penting. Kadang-kadang penting untuk mempertimbangkan keandalan sebagai dasar untuk perbandingan.
Mengambil melihat lebih dekat pada tingkat RAID kita amati bahwa sebagian besar tingkat yang mirip satu sama lain. RAID level 1 dan RAID level 3 array disk dapat dilihat sebagai subclass dari tingkat RAID 5 array disk. Juga RAID tingkat 2 dan RAID tingkat 4 array disk umumnya ditemukan akan kalah dengan RAID level 5 array disk. Oleh karena itu masalah memilih di antara tingkat RAID 1 sampai 5 adalah bagian dari masalah yang lebih umum memilih ukuran kelompok paritas yang sesuai dan Unit striping untuk tingkat RAID 5 array disk.
Beberapa Perbandingan
Diberikan di bawah ini adalah tabel yang membandingkan throughput berbagai skema redundansi untuk empat jenis I / O permintaan. I / O permintaan pada dasarnya membaca dan menulis yang dibagi menjadi kecil (membaca & menulis) dan yang besar. Mengingat fakta bahwa data kami telah tersebar di beberapa disk (data striping), kecil mengacu pada permintaan I / O dari satu unit striping sementara permintaan I / O besar mengacu pada permintaan dari satu garis penuh (satu unit garis dari masing-masing disk dalam kelompok koreksi kesalahan).
G: Jumlah disk dalam grup koreksi kesalahan.
Tabel di atas tabulates throughput maksimum per dolar relatif tingkat 0 untuk tingkat RAID 0, 1, 3, 5 dan 6. Untuk tujuan praktis kita mempertimbangkan tingkat RAID 2 & 4 kalah dengan RAID level 5 array disk, sehingga kita tidak menunjukkan perbandingan. Biaya sistem berbanding lurus dengan jumlah disk menggunakan dalam array disk. Dengan demikian tabel menunjukkan kepada kita bahwa diberikan tingkat RAID biaya setara 0 dan RAID level 1 sistem, tingkat RAID 1 sistem dapat mempertahankan setengah jumlah menulis kecil per detik bahwa RAID tingkat 0 sistem dapat mempertahankan. Ekuivalen biaya kecil menulis dua kali lebih mahal di tingkat RAID 1 sistem seperti pada tingkat RAID 0 sistem.
Tabel tersebut juga menunjukkan efisiensi penyimpanan setiap tingkat RAID. Efisiensi penyimpanan adalah sekitar terbalik biaya dari setiap unit kapasitas pengguna relatif terhadap tingkat RAID 0 sistem. The efisiensi penyimpanan sama dengan metrik kinerja / biaya untuk menulis besar.
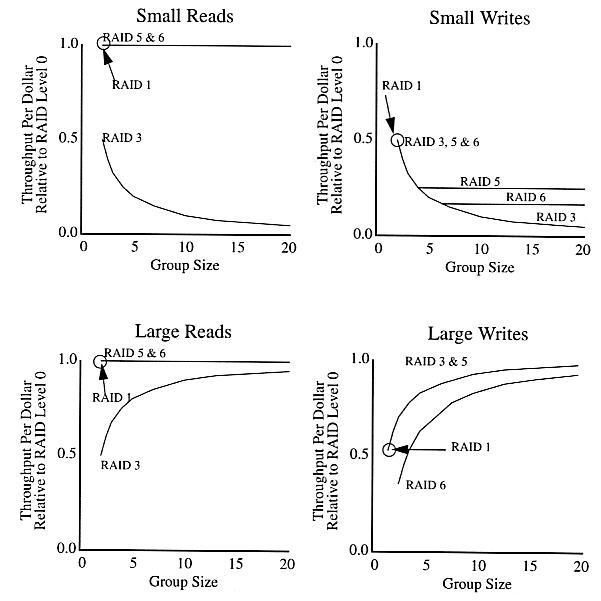 Sumber: Referensi 1
Sumber: Referensi 1
Angka-angka di atas grafik metrik kinerja / biaya dari tabel di atas untuk tingkat RAID 1, 3, 5 dan 6 pada rentang ukuran kelompok paritas. Kinerja / biaya tingkat RAID 1 sistem setara dengan kinerja / biaya tingkat RAID 5 sistem ketika ukuran kelompok paritas sama dengan 2. Kinerja / biaya tingkat RAID 3 sistem selalu kurang dari atau sama dengan kinerja / biaya tingkat RAID 5 sistem. Hal ini diharapkan mengingat bahwa RAID tingkat 3 sistem adalah subclass dari tingkat RAID 5 sistem diturunkan dengan membatasi ukuran unit striping sehingga semua permintaan akses persis garis paritas data. Karena konfigurasi RAID tingkat 5 sistem tidak dikenakan pembatasan tersebut, kinerja / biaya tingkat RAID 5 sistem tidak pernah bisa kurang dari itu sistem RAID tingkat setara 3. Tentu saja generalisasi seperti khusus untuk model array disk yang digunakan dalam percobaan di atas. Pada kenyataannya, implementasi khusus dari RAID level 3 sistem dapat memiliki kinerja / biaya yang lebih baik daripada implementasi khusus dari sistem tingkat RAID 5.
Pertanyaan yang tingkat RAID untuk menggunakan lebih baik dinyatakan sebagai pertanyaan konfigurasi yang lebih umum mengenai ukuran kelompok paritas dan striping satuan. Untuk ukuran kelompok paritas 2, mirroring yang diinginkan, sedangkan untuk yang sangat kecil satuan striping RAID level 3 akan cocok.
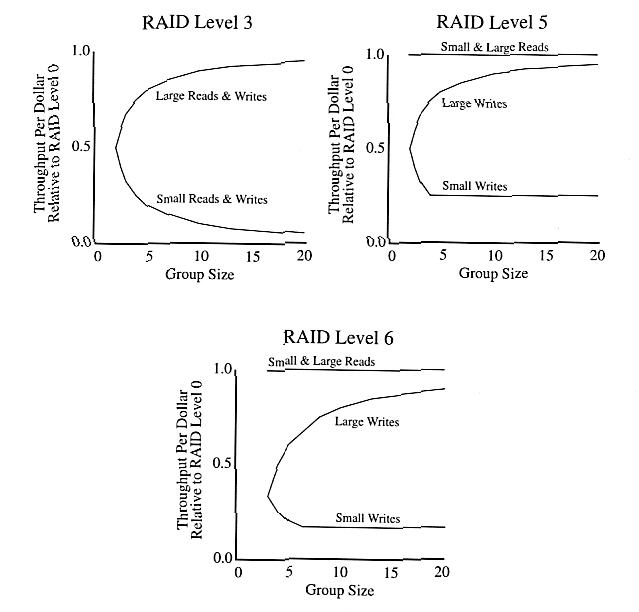
Gambar di bawah ini plot metrik kinerja / biaya dari tabel di atas untuk tingkat RAID 3, 5 & 6.
RAID Z
Raid Z dan RAID Z2 adalah penemuan Sun Micro System. RAID Z memiliki semua manfaat dari RAID 5 dan fitur lainnya yang membuatnya jauh lebih unggul. Seperti dengan RAID 5, RAID Z dapat mendukung
sejumlah hard disk yang bekerja sama dan satu disk untuk redudansi. Jumlah minimum dari hard disk adalah tiga dan hanya satu yang bisa down pada suatu waktu. Jika lebih dari satu hard disk rusak pada saat yang sama, maka kita beresiko kehilangan data.
Kelebihan: Memiliki semua kelebihan dari RAID 5 dan fitur lainnya.
Kelemahan: Hanya dapat digunakan dengan OS berbasis Open Solaris seperti Nexenta dan atau sistem berbasis BSD seperti FreeBSD.
Kapan menggunakan: RAID Z adalah level RAID terbaik untuk penyimpanan/storage. Pada dasarnya RAID Z melengkapi hampir semua kekurangan dari RAID tingkat sebelumnya dan menambahkan banyak fitur
baru. Namun hanya bisa digunakan dengan sistem berbasis Solaris dan BSD. RAID Z sangat baik untuk digunakan dalam NAS / lainnya untuk penyimpanan data berskala besar.
RAID Z2
Raid Z2 hampir identik dengan Raid Z dan mirip dengan RAID 6. Dalam RAID Z2, meski dua hard disk bisa down di waktu bersamaan namun data akan tetap aman dan mudah diakses. Sama seperti RAID Z,
RAID Z2 jauh lebih unggul dengan RAID 6 karena di dalamnya terdapat banyak fitur lainnya. Jumlah minimum drive untuk menggunakan RAID Z2 adalah empat.
Keuntungan: Data lebih aman meski dua drive bisa down pada saat yang sama bukan hanya satu. Memiliki semua manfaat dari RAID Z.
Kekurangan: Dua hard disk digunakan untuk paritas, sehingga ukuran jumlah gabungan space sangat terbatas. Hanya dapat digunakan dengan OS berbasis Open Solaris seperti Nexenta dan atau sistem berbasis BSD seperti FreeBSD.
Kapan menggunakan:Sama seperti RAID Z tetapi dilengkapi dengan tambahan tingkat keamanan. Tidak untuk digunakan jika butuh space yang besar.
RAID Level 0 +1: Sebuah Cermin Stripes bukan merupakan tingkat RAID asli, tetapi merupakan gabungan dua RAID yaitu RAID 0 stripes yang diciptakan, dan RAID 1 mirror. Digunakan pada data replikasi dan sharing antar disk.
RAID Level 10: Sebuah Stripe of Mirrors
Tak satu pun dari tingkat RAID asli, beberapa mirror RAID 1 diciptakan, dan RAID 0 stripe dibuat pada tingkatan ini. RAID 10 diklasifikasikan sebagai controller RAID futuristik dengan Kehandalan tinggi dan kinerja sangat tertanam dalam RAID controller tunggal. Persyaratan minimum untuk membentuk tingkat RAID 10 controller 4 data disk. Pelaksanaan RAID 10 didasarkan pada bergaris array RAID 1 segmen array, dengan hampir tingkat toleransi kesalahan yang sama seperti RAID 1. RAID 10 array controller dan cocok untuk tanpa kompromi ketersediaan dan throughput tinggi sangat diperlukan sistem dan lingkungan.
RAID Level 7
Sebuah merek dagang Penyimpanan Computer Corporation yang menambahkan caching untuk Tingkat 3 atau 4. RAID7 membuat sistem operasi sebagai controller, caching menggunakan jalur cepat. RAID 7 adalah array asynchrony Dioptimalkan untuk tinggi saya / kecepatan transfer data dan O dianggap sebagai RAID controller dikelola paling tersedia. Menulis kinerja keseluruhan juga dikenal menjadi 50% sampai 90% lebih baik dan diperbaiki dibandingkan array tingkat poros tunggal tanpa transferensi data tambahan yang diperlukan untuk penanganan paritas.
RAID 0 +3
RAID level 0 3 atau RAID tingkat 03 adalah array paritas khusus di disk bergaris. Setiap blok data di tingkat 3 RAID ini dipecah antara RAID 0 array mana potongan-potongan yang lebih kecil bergaris di seluruh disk.

RAID 30
RAID level 30 juga dikenal sebagai striping array paritas khusus. Ini adalah kombinasi dari RAID level 3 dan tingkat RAID 0. RAID 30 memberikan kecepatan transfer data yang tinggi, dikombinasikan dengan keandalan data yang tinggi. RAID 30 adalah paling baik dilaksanakan pada dua array disk RAID 3 dengan data garis-garis di kedua array disk. RAID 30 memecah data ke dalam blok yang lebih kecil, dan kemudian garis-garis blok data untuk setiap set 3 raid RAID. RAID 3 memecah data ke dalam blok-blok yang lebih kecil, menghitung paritas dengan melakukan ATAU Eksklusif di blok, dan kemudian menulis blok untuk semua kecuali satu drive dalam array. Bit paritas dibuat menggunakan OR eksklusif kemudian ditulis ke drive terakhir dalam tiap array RAID 3. Ukuran setiap blok ditentukan oleh parameter ukuran jalur, yang mengatur kapan RAID dibuat.
Satu drive dari masing-masing yang mendasari RAID 3 set bisa gagal. Sampai drive gagal diganti drive lain dalam set yang mengalami seperti kegagalan adalah satu titik kegagalan untuk seluruh RAID 30 array. Dengan kata lain, jika salah satu drive gagal, semua data disimpan di seluruh array hilang. Waktu yang dihabiskan dalam pemulihan (mendeteksi dan menanggapi kegagalan drive, dan membangun kembali proses ke drive baru terpasang) merupakan periode kerentanan terhadap set RAID.
 RAID 50 (RAID 5 +0)
RAID 50 (RAID 5 +0)
Sebuah RAID 50 menggabungkan lurus blok -tingkat striping RAID 0 dengan paritas terdistribusi RAID 5. Ini adalah RAID 0 array bergaris di RAID 5 elemen. Hal ini membutuhkan setidaknya 6 drive. Berikut adalah contoh di mana tiga koleksi 240 GB RAID 5s bergaris sama untuk membuat 720 GB ruang penyimpanan total:
Satu drive dari masing-masing 5 set RAID bisa gagal tanpa kehilangan data. Namun, jika drive gagal tidak diganti, drive yang tersisa dalam set kemudian menjadi satu titik kegagalan untuk seluruh array. Jika salah satu drive yang gagal, semua data disimpan di seluruh array hilang. Waktu yang dihabiskan dalam pemulihan (mendeteksi dan menanggapi kegagalan drive, dan membangun kembali proses ke drive baru terpasang) merupakan periode kerentanan terhadap set RAID.
 RAID 50 meningkatkan terhadap kinerja RAID 5 khususnya selama menulis,
dan memberikan toleransi kesalahan yang lebih baik dari tingkat RAID
tunggal tidak. Tingkat ini dianjurkan untuk aplikasi yang memerlukan
toleransi kesalahan yang tinggi, kapasitas dan kinerja posisi acak.
Karena jumlah drive pada RAID set meningkat, dan peningkatan kapasitas
drive, ini dampak waktu pemulihan kesalahan-Sejalan sebagai interval
untuk membangun kembali meningkat set RAID. Karena jumlah drive pada
RAID set meningkat, dan peningkatan kapasitas drive, ini dampak waktu
pemulihan kesalahan-Sejalan sebagai interval untuk membangun kembali
meningkat set RAID.
RAID 50 meningkatkan terhadap kinerja RAID 5 khususnya selama menulis,
dan memberikan toleransi kesalahan yang lebih baik dari tingkat RAID
tunggal tidak. Tingkat ini dianjurkan untuk aplikasi yang memerlukan
toleransi kesalahan yang tinggi, kapasitas dan kinerja posisi acak.
Karena jumlah drive pada RAID set meningkat, dan peningkatan kapasitas
drive, ini dampak waktu pemulihan kesalahan-Sejalan sebagai interval
untuk membangun kembali meningkat set RAID. Karena jumlah drive pada
RAID set meningkat, dan peningkatan kapasitas drive, ini dampak waktu
pemulihan kesalahan-Sejalan sebagai interval untuk membangun kembali
meningkat set RAID.
RAID 51
Sebuah RAID51 atau RAID5 +1 adalah sebuah array yang terdiri dari dua RAID 5 yang merupakan cermin satu sama lain. Umumnya konfigurasi ini digunakan supaya setiap RAID5 berada pada controller yang terpisah. Dalam konfigurasi ini membaca dan menulis yang seimbang di kedua RAID5s. Beberapa controller mendukung RAID51 di beberapa saluran dan kartu dengan mengisyaratkan untuk menjaga irisan yang berbeda disinkronisasi. Namun suatu RAID51 juga dapat dilakukan dengan menggunakan teknik RAID berlapis. Dalam konfigurasi ini, kedua RAID5 itu tidak tahu bahwa mereka adalah cermin dari satu sama lain dan RAID1 tidak tahu bahwa disk yang mendasarinya adalah RAID5’s. Konfigurasi ini dapat mempertahankan dua kegagalan disk (satu per array) sebelum data akan hilang. Jumlah maksimum ruang dari RAID51 adalah (N) dimana N adalah ukuran dari RAID5 individu
 RAID 60 (RAID 6 +0)
RAID 60 (RAID 6 +0)
Sebuah RAID 60 menggabungkan striping blok-tingkat lurus RAID 0 dengan paritas ganda terdistribusi RAID 6. Artinya, RAID 0 array bergaris di RAID 6 elemen. Hal ini membutuhkan setidaknya 8 disk. Berikut adalah contoh di mana dua kumpulan RAID 6s 240 GB yang bergaris sama untuk membuat 480 GB ruang penyimpanan total:
Karena didasarkan pada RAID 6, dua disk dari masing-masing 6 set RAID bisa gagal tanpa kehilangan data. Juga kegagalan sementara satu disk adalah membangun kembali dalam satu RAID 6 tetapkan tidak akan mengakibatkan hilangnya data. RAID 60 telah meningkatkan toleransi kesalahan, setiap dua drive bisa gagal tanpa kehilangan data dan sampai empat total selama itu hanya dua dari masing-masing sub-array RAID6. Striping membantu meningkatkan kapasitas dan kinerja tanpa menambahkan disk untuk setiap set 6 RAID (yang akan menurunkan ketersediaan data dan dapat mempengaruhi kinerja). RAID 60 meningkatkan atas kinerja RAID 6. Terlepas dari kenyataan bahwa RAID 60 sedikit lebih lambat dari RAID 50 dalam hal menulis karena overhead ditambahkan perhitungan paritas lebih, ketika data keamanan yang bersangkutan ini penurunan kinerja mungkin dapat diabaikan.

RAID S
Juga disebut Paritas RAID, stripe yang dimiliki oleh sistem RAID paritas EMC Corporation digunakan dalam sistem penyimpanan Symmetrix nya
pengertian Istilah penting Dalam Raid yaitu:
* Data Striping: sebuah metoda untuk menyatukan beberapa harddisk untuk menjadi sebuah harddisk virtual. Striping pada dasarnya membuat partisi pada setiap harddisk menjadi banyak stripe (potongan kecil) yang mulai dari 512byte atau beberapa megabyte. Masing-masing stripe ini akan di tumpuk satu sama lain secara berputar / bergilir antar harddisk, oleh karena itu gabungan tempat penyimpanan di harddisk akan berurutan (berselang seling) dalam bentuk stripe dari setiap harddisk. Tergantung pada kebutuhan aplikasi, I/O atau data intensif, akan menentukan besar atau kecil-nya stripe yang akan digunakan.
* Redudansi adalah kejadian berulangnya data atau kumpulan data yang sama dalam sebuah database yang mengakibatkan pemborosan media penyimpanan
* Mirroring (penyalinan data ke lebih dari satu buah hard disk),
Striping (pemecahan data ke beberapa hard disk) dan juga koreksi kesalahan, di mana redundansi data disimpan untuk mengizinkan kesalahan dan masalah untuk dapat dideteksi dan mungkin dikoreksi (lebih umum disebut sebagai teknik fault tolerance/toleransi kesalahan)
* code hamming atau kode hamming: sistem pengkoreksian kesalahan kode Hamming. Yang ditemukan oleh Prof. Wesley Richard Hamming di laboratorium bell dengan menggunakan diagram Venn.
Dengan tiga buah lingkaran, yang berpotongan, terdapat tujuh kompartemen. Kita akan memberikan 4 buah bit data ke kompartemen yang terletak di tengah (Gambar 2a). kompartemen sisanya diisi dengan apa yang kita sebut bit paritas. Setiap bit paritas dipilih sehingga bilangan 1 dalam lingkaran berjumlah genap (Gambar 2b). Jadi, karena lingkaran A terdiri dari tiga buah bilangan 1, maka bit paritas dalam lingkaran itu disetel menjadi 1. sekarang, apabila suatu error mengubah salah satu bit data (Gambar 2c), maka error itu akan dengan mudah ditemukan.
 Untuk mencapai
karakteristik ini, maka bit data dan bit cek diatur menjadi word 12- bit
seperti yang dapat dilihat pada gambar 3. posisi-posisi bit diberi nomor dari 1
hingga 12. posisi-posisi bit yang memiliki bilangan posisinya pangkat 2
tersebut dikenal sebagai bit-bit check. Bit-bit check ini dihitung
sebagai berikut, dengan
symbol menandakan operasi
exclusive-or :
Untuk mencapai
karakteristik ini, maka bit data dan bit cek diatur menjadi word 12- bit
seperti yang dapat dilihat pada gambar 3. posisi-posisi bit diberi nomor dari 1
hingga 12. posisi-posisi bit yang memiliki bilangan posisinya pangkat 2
tersebut dikenal sebagai bit-bit check. Bit-bit check ini dihitung
sebagai berikut, dengan
symbol menandakan operasi
exclusive-or :
 C1 =
M1 M2
M4 M5 M7
C1 =
M1 M2
M4 M5 M7
Setiap bit cek beroperasi pada setiap bit data yang
nomor posisinya berisi bilangan 1 pada kolomnya. Jadi, posisi-posisi bit data
3, 5, 7, 9 dan 11semuanya berisi suku 2 ;
posisi-posisi bit 3, 6, 7, 10, dan 11 semuanya berisi suku 2
;
posisi-posisi bit 3, 6, 7, 10, dan 11 semuanya berisi suku 2 ;
Posisi-posisi bit 5, 6, 7, dan 12 seluruhnya berisi suku 2
;
Posisi-posisi bit 5, 6, 7, dan 12 seluruhnya berisi suku 2 ; dan
posisi-posisi bit 9, 10, 11, dan 12 berisi suku 2 ;
Ditinjau dari sisi lain, posisi bit n diperiksa oleh bit-bit C
; dan
posisi-posisi bit 9, 10, 11, dan 12 berisi suku 2 ;
Ditinjau dari sisi lain, posisi bit n diperiksa oleh bit-bit C sehingga
sehingga
 = n.
Misalnya, posisi bit 7 diperiksa oleh bit-bit yang berada pada posisi 4, 2, dan
1; dan 7 = 4 + 2 + 1.
= n.
Misalnya, posisi bit 7 diperiksa oleh bit-bit yang berada pada posisi 4, 2, dan
1; dan 7 = 4 + 2 + 1.
* Code Reed Solomon: algoritma Reed-Solomon secara luas digunakan dalam telekomunikasi dan penyimpanan data. Ini adalah bagian dari semua CD dan DVD pembaca, RAID 6 implementasi, dan bahkan sebagian besar barcode, di mana ia memberikan koreksi kesalahan dan pemulihan data. Hal ini juga melindungi data telemetri yang dikirim oleh deep-space probe seperti Voyagers I dan II. Dan itu digunakan oleh ADSL dan DTV hardware untuk memastikan data kesetiaan selama transmisi dan penerimaan. Algoritma ini merupakan gagasan dari Irving Reed dan Gustave Solomon, keduanya insinyur di MIT Lincoln Labs. Pengenalan publik adalah melalui 1960 kertas "Kode Polinomial Tertentu Hingga Fields." Yang cukup menarik, kertas yang tidak memberikan cara yang efisien untuk memecahkan kode kesalahan disajikan. Sebuah skema decoding yang lebih baik dikembangkan pada tahun 1969 oleh Elwyn Berklekamp dan James Massey.
Konsep RAID pertama kali didefinisikan pada tahun 1988, ketika sekelompok ilmuwan komputer di Universitas California Berkeley, (David Patterson, Garth Gibson, dan Randy Katz) menerbitkan makalah berjudul “A Kasus Redundant Array Inexpensive Disk (RAID)". Kebutuhan RAID dapat diringkas dalam dua poin di bawah ini. Dua kata kunci yang Redundant Array dan.
- Array beberapa disk diakses secara paralel akan memberikan throughput yang lebih besar daripada disk tunggal.
- Data yang berlebihan pada beberapa disk memberikan toleransi kesalahan.
Dengan beberapa disk dan skema redundansi yang cocok, sistem anda dapat tetap up dan berjalan ketika sebuah disk gagal, dan bahkan ketika disk pengganti yang diinstal dan data dipulihkan.
Untuk membuat hemat biaya konfigurasi RAID yang optimal, kita perlu untuk secara bersamaan mencapai tujuan berikut:
- Maksimalkan jumlah disk yang diakses secara paralel.
- Meminimalkan jumlah ruang disk yang digunakan untuk data yang berlebihan.
- Meminimalkan overhead yang diperlukan untuk mencapai tujuan di atas
Ada 2 konsep penting untuk dipahami dalam desain dan implementasi array disk:
1. Data striping, untuk meningkatkan kinerja.
2. redundansi untuk meningkatkan ketersediaan.
Data Striping Data striping transparan mendistribusikan data melalui beberapa disk untuk membuat mereka tampil sebagai cepat, besar disk tunggal. Striping meningkatkan agregat I / O kinerja dengan memungkinkan beberapa I / Os untuk dilayani secara paralel. Ada 2 aspek paralelisme ini. - Beberapa, permintaan independen dapat dilayani secara paralel oleh disk terpisah. Hal ini mengurangi waktu antrian dilihat oleh I / O permintaan.
- Single, beberapa permintaan blok dapat dilayani oleh beberapa disk bertindak dalam koordinasi. Hal ini meningkatkan kecepatan transfer efektif dilihat oleh satu permintaan. Manfaat kinerja meningkat dengan jumlah disk di array. Sayangnya, sejumlah besar disk menurunkan keandalan keseluruhan array disk.
2. cara di mana data yang berlebihan dihitung dan disimpan di array disk.
Data interleaving dapat berupa berbutir halus atau berbutir kasar.
Baik-baik saja array disk berbutir konseptual data yang interleave dalam unit relatif kecil sehingga semua I / O permintaan, terlepas dari ukuran mereka, mengakses semua disk dalam array disk. Hal ini menyebabkan kecepatan transfer data sangat tinggi untuk semua I / O permintaan namun memiliki kelemahan bahwa hanya satu logis I / O permintaan bisa dalam pelayanan pada waktu tertentu dan semua disk harus buang waktu positioning untuk setiap permintaan.
Array disk berbutir kasar interleave data dalam unit relatif besar sehingga saya kecil / O permintaan memerlukan akses hanya sejumlah kecil dari disk sementara permintaan besar dapat mengakses semua disk dalam array disk. Hal ini memungkinkan beberapa permintaan kecil untuk dilayani secara bersamaan sementara masih memungkinkan permintaan besar untuk melihat kecepatan transfer lebih tinggi diberikan dengan menggunakan beberapa disk.
Penggabungan redundansi dalam array disk membawa dua masalah:
1. Memilih metode untuk menghitung informasi yang berlebihan. Kebanyakan berlebihan disk array saat ini menggunakan paritas, meskipun beberapa menggunakan kode Hamming atau Reed-Solomon.
2. Memilih metode untuk distribusi informasi yang berlebihan di seluruh array disk. Metode distribusi dapat diklasifikasikan menjadi 2 skema yang berbeda:
- Skema yang berkonsentrasi informasi yang berlebihan pada sejumlah kecil disk.
- Skema yang mendistribusikan informasi yang berlebihan merata di semua disk.
Ada banyak jenis RAID dan beberapa yang penting diperkenalkan di bawah ini:
- Non-Redundant ( RAID Level 0)
Sebuah array disk non-redundant, atau RAID tingkat 0, memiliki biaya terendah dari setiap organisasi RAID karena tidak menggunakan redundansi sama sekali. Skema ini menawarkan performa terbaik karena tidak pernah perlu memperbarui informasi yang berlebihan. Anehnya, ia tidak memiliki kinerja terbaik. Skema redundansi yang menduplikasi data, seperti mirroring, dapat melakukan lebih baik pada membaca dengan menjadwalkan selektif permintaan pada disk dengan terpendek diharapkan seek dan rotasi penundaan. Tanpa, redundansi, kegagalan disk tunggal akan mengakibatkan data-rugi. Array disk non-redundant yang banyak digunakan dalam lingkungan super-komputasi di mana kinerja dan kapasitas, daripada kehandalan, merupakan keprihatinan utama.
Blok berurutan data ditulis di beberapa disk dalam garis-garis, sebagai berikut:
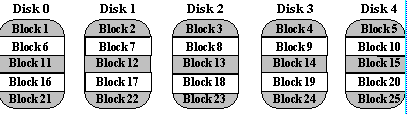 Sumber: Referensi 2
Sumber: Referensi 2 -
Kelebihan:
- RAID 0 menggunakan ruang hard disk secara maksimal karena tidak ada redundasi data.
- RAID 0 punya kecepatan yang lebih karena lebih banyak ruang dari dua hard disk yang dijadikan satu.
Kekurangan:- Tidak ada perlindungan. Jadi jika kita kehilangan satu hard disk tunggal, data kita akan hilang.
- Contoh: Misalnya: Kita membutuhkan suatu partisi dengan ukuran 500GB. Harga sebuah harddisk berukuran 100GB adalah Rp.500.000,-
sedangkan harga harddisk berukuran 500GB adalah Rp.5.000.000,-. Nah,
kita dapat membetuk suatu partisi berukuran 500GB dari 5 unit harddisk
berukuran 100GB dengan menggunakan RAID 0. Tentunya skenario ini lebih
murah karena memakan biaya lebih murah: 5 x Rp.500.000,-
= Rp.2.500.000,-. Lebih murah daripada harus membeli harddisk yang
berukuran 500GB. Itulah kenapa pada awalnya disebut redundant array of
inexpensive disk.
Mirroring ( RAID Level 1)
Solusi tradisional, yang disebut mirroring atau shadowing, menggunakan dua kali lebih banyak disk sebagai disk array non-berlebihan. setiap kali data ditulis ke disk data yang sama juga ditulis ke disk berlebihan, sehingga selalu ada dua salinan informasi tersebut. Ketika data dibaca, itu dapat diambil dari disk dengan antrian yang lebih pendek, mencari dan penundaan rotasi. Jika sebuah disk gagal, salinan lain digunakan untuk permintaan layanan. Mirroring sering digunakan dalam aplikasi database di mana ketersediaan dan waktu transaksi yang lebih penting daripada efisiensi penyimpanan. - Kelebihan: Redundansi dan Kecepatan.
- Kekurangan: Space hard disk tidak digunakan secara efisien. Karena kedua hard disk adalah salinan satu sama lain, hanya setengah dari ukuran jumlah gabungan yang digunakan
- Contoh:
Sebuah server memiliki 2 unit harddisk yang berkapasitas masing-masing 80GB dan dikonfigurasi RAID 1. Setelah beberapa tahun, salah satu harddisknya mengalami kerusakan fisik. Namun data pada harddisk lainnya masih dapat dibaca, sehingga data masih dapat diselamatkan selama bukan semua harddisk yang mengalami kerusakan fisik secara bersamaan.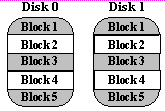 Sumber: Referensi 2
Sumber: Referensi 2
Sistem memori telah menyediakan pemulihan dari komponen gagal dengan biaya yang jauh kurang dari mirroring dengan menggunakan kode Hamming. Kode Hamming berisi paritas untuk subset tumpang tindih yang berbeda komponen. Dalam salah satu versi dari skema ini, empat disk membutuhkan tiga disk berlebihan, kurang satu dari mirroring. Karena jumlah disk berlebihan sebanding dengan log dari jumlah total disk pada sistem, efisiensi penyimpanan meningkat karena jumlah disk data yang meningkat.
Jika komponen tunggal gagal, beberapa komponen paritas akan memiliki nilai yang tidak konsisten, dan komponen gagal adalah yang dimiliki bersama oleh masing-masing bagian yang salah. Informasi yang hilang ditemukan oleh membaca komponen lain dalam subset, termasuk komponen paritas, dan pengaturan bit hilang dengan 0 atau 1 untuk menciptakan nilai paritas tepat untuk bagian itu. Dengan demikian, beberapa disk berlebihan yang diperlukan untuk mengidentifikasi disk gagal, tapi hanya satu yang dibutuhkan untuk memulihkan informasi yang hilang.
Dalam Anda tidak menyadari paritas, Anda bisa memikirkan disk berlebihan sebagai memiliki jumlah semua data dalam disk lainnya. Ketika sebuah disk gagal, Anda dapat mengurangi semua data pada disk yang baik membentuk paritas disk; informasi yang tersisa harus informasi yang hilang. Paritas hanyalah jumlah ini modulo 2.
Sebuah sistem RAID 2 biasanya akan memiliki banyak disk data kata ukuran komputer, biasanya 32. Selain itu, RAID 2 membutuhkan penggunaan disk tambahan untuk menyimpan kode error-correcting untuk redundansi. Dengan 32 disk data, sistem RAID 2 akan membutuhkan 7 disk tambahan untuk ECC Hamming-kode. Seperti sebuah array dari 39 disk adalah subyek paten AS diberikan kepada Unisys Corporation di tahun 1988, tapi tidak ada produk komersial yang pernah dirilis.
Untuk sejumlah alasan, termasuk fakta bahwa disk drive modern mengandung ECC internal mereka sendiri, RAID 2 bukan skema array disk praktis. - Contoh:
Kita memiliki 5 harddisk (sebut saja harddisk A,B,C, D, dan E) dengan ukuran yang sama, masing-masing 40GB. Jika kita mengkonfigurasi keempat harddisk tersebut dengan RAID 2, maka kapasitas yang didapat adalah: 2 x 40GB = 80GB (dari harddisk A dan B). Sedangkan harddisk C, D, dan E tidak digunakan untuk penyimpanan data, melainkan hanya untuk menyimpan informasi pariti hamming dari dua harddisk lainnya: A, dan B. Ketika terjadi kerusakan fisik pada salah satu harddisk utama (A atau B), maka data tetap dapat dibaca dengan memperhitungkan pariti kode hamming yang ada di harddisk C, D, dan E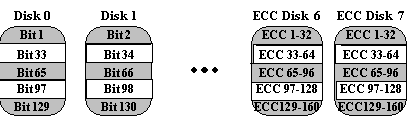 Sumber: Referensi 2
Sumber: Referensi 2
Satu dapat memperbaiki memori-gaya array ECC disk dengan mencatat bahwa, tidak seperti kegagalan komponen memori, kontroler disk dapat dengan mudah mengidentifikasi mana disk telah gagal. Dengan demikian, seseorang dapat menggunakan paritas tunggal daripada satu set disk paritas untuk memulihkan informasi yang hilang.
Dalam array disk paritas bit-interleaved,, data secara konseptual interleaved bit-wise atas disk data, dan paritas disk tunggal ditambahkan untuk mentolerir kegagalan disk tunggal. Setiap membaca permintaan mengakses semua disk data dan setiap permintaan menulis mengakses semua disk data dan paritas disk. Dengan demikian, hanya satu permintaan dapat dilayani pada suatu waktu. Karena paritas disk hanya berisi paritas dan tidak ada data, paritas disk tidak dapat berpartisipasi pada membaca, sehingga menghasilkan kinerja membaca sedikit lebih rendah daripada skema redundansi yang mendistribusikan paritas dan data melalui semua disk. Bit-interleaved, array disk paritas yang sering digunakan dalam aplikasi yang membutuhkan bandwidth tinggi tetapi tidak tinggi I / O tarif. Mereka juga mudah untuk diterapkan dari tingkat RAID 4, 5, dan 6.
Di sini, paritas disk ditulis dalam cara yang sama seperti bit paritas di biasa Random Access Memory (RAM), di mana itu adalah Eksklusif Atau dari 8, 16 atau 32 bit data. Dalam RAM, paritas digunakan untuk mendeteksi kesalahan data tunggal-bit, tetapi tidak dapat memperbaikinya karena tidak ada informasi yang tersedia untuk menentukan bit tidak benar. Dengan disk drive, namun, kami bergantung pada disk controller melaporkan kesalahan membaca data. Mengetahui disk data yang hilang, kita bisa merekonstruksi itu sebagai Exclusive Or (XOR) dari semua disk data yang tersisa ditambah paritas disk.
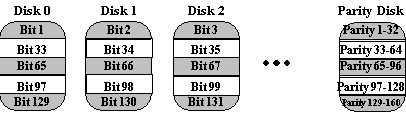 Sumber: Referensi 2
Sumber: Referensi 2
Disk 0 Disk 1 Disk 2 Disk 3 Paritas
0 1 1 1 1
Paritas bit adalah XOR dari empat bit data, yang dapat dihitung dengan menambahkan mereka dan menulis 0 jika jumlahnya bahkan dan 1 jika ganjil. Berikut jumlah Disk 0 melalui Disk 3 adalah "3", sehingga paritas adalah 1. Sekarang jika kita mencoba untuk membaca kembali data ini, dan menemukan bahwa Disk 2 memberikan kesalahan membaca, kita bisa merekonstruksi Disk 2 sebagai XOR dari semua disk lain, termasuk paritas. Dalam contoh ini, jumlah Disk 0, 1, 3 dan Paritas adalah "3", sehingga data pada Disk 2 harus 1. - Contoh kasus:
Kita memiliki 4 harddisk (sebut saja harddisk A,B,C, dan D) dengan ukuran yang sama, masing-masing 40GB. Jika kita mengkonfigurasi keempat harddisk tersebut dengan RAID 3, maka kapasitas yang didapat adalah: 3 x 40GB = 120GB. Sedangkan harddisk D tidak digunakan untuk penyimpanan data, melainkan hanya untuk menyimpan informasi parity dari ketiga harddisk lainnya: A, B, dan C. Ketika terjadi kerusakan fisik pada salah satu harddisk utama (A, B, atau C), maka data tetap dapat dibaca dengan memperhitungkan parity yang ada di harddisk D. Namun, jika harddisk D yang mengalami kerusakan, maka data tetap dapat dibaca dari ketiga harddisk lainnya
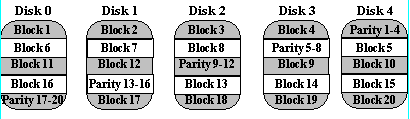
Blok-Interleaved Parity ( RAID Level 4)
Blok-disisipkan, susunan paritas disk mirip dengan, susunan disk paritas bit interleaved-kecuali data yang disisipkan di disk ukuran sewenang-wenang bukan dalam bit. Ukuran blok ini disebut unit striping. Baca permintaan lebih kecil dari akses Unit striping hanya disk data tunggal. Menulis permintaan harus memperbarui blok data yang diminta dan juga harus menghitung dan memperbarui blok paritas. Untuk menulis besar yang menyentuh blok pada semua disk, paritas mudah dihitung dengan or'ing eksklusif-data baru untuk setiap disk. Untuk menulis permintaan kecil yang memperbarui hanya satu disk data, paritas dihitung dengan mencatat bagaimana data baru berbeda dari data lama dan menerapkan perbedaan ke blok paritas. Menulis permintaan kecil sehingga membutuhkan empat disk I / Os: satu untuk menulis data baru, dua untuk membaca data lama dan paritas tua untuk menghitung paritas baru, dan satu untuk menulis paritas baru. Hal ini disebut sebagai prosedur read-memodifikasi-menulis. Karena, berbagai disk paritas blok interleaved-hanya memiliki satu disk paritas, yang harus diperbarui pada semua menulis operasi, paritas disk dapat dengan mudah menjadi hambatan. Karena keterbatasan ini, didistribusikan array yang disk paritas blok interleaved-secara universal disukai daripada, array disk paritas blok-disisipkan. Kekurangan dari RAID 4 adalah dimungkinkan terjadi bottleneck karena paritas data disimpan dalam hard disk tersendiri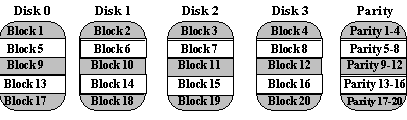 Sumber: Referensi 2
Sumber: Referensi 2
Array didistribusikan-disk paritas blok-disisipkan menghilangkan disk paritas hambatan hadir dalam array disk paritas blok interleaved-dengan mendistribusikan paritas seragam atas semua disk. Tambahan, sering diabaikan keuntungan untuk mendistribusikan paritas adalah bahwa hal itu juga mendistribusikan data melalui semua disk daripada lebih dari semua kecuali satu. Hal ini memungkinkan semua disk untuk berpartisipasi dalam melayani operasi baca berbeda dengan redundansi skema dengan disk paritas khusus di mana paritas disk tidak dapat berpartisipasi dalam melayani permintaan baca. Blok-interleaved array disk didistribusikan-paritas memiliki yang terbaik membaca kecil, menulis kinerja besar setiap array redundansi disk. Menulis permintaan kecil agak tidak efisien dibandingkan dengan skema redundansi seperti mirroring Namun, karena kebutuhan untuk melakukan operasi read-memodifikasi-menulis untuk memperbarui paritas. Ini adalah kelemahan kinerja utama dari tingkat RAID 5 array disk.
Metode yang tepat digunakan untuk mendistribusikan paritas blok interleaved-didistribusikan-paritas disk array dapat mempengaruhi kinerja. Gambar berikut mengilustrasikan distribusi paritas kiri simetris.
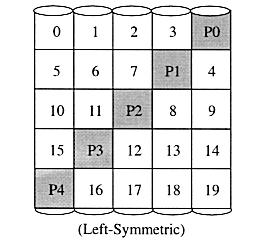 Setiap persegi sesuai dengan unit stripe. Setiap kolom dari kotak sesuai dengan disk. P0 menghitung paritas lebih dari unit stripe 0, 1, 2 dan 3; P1 menghitung paritas lebih dari unit stripe 4, 5, 6, dan 7 dll (sumber: Referensi 1 )
Setiap persegi sesuai dengan unit stripe. Setiap kolom dari kotak sesuai dengan disk. P0 menghitung paritas lebih dari unit stripe 0, 1, 2 dan 3; P1 menghitung paritas lebih dari unit stripe 4, 5, 6, dan 7 dll (sumber: Referensi 1 )
Sebuah properti yang berguna distribusi paritas kiri simetris adalah bahwa setiap kali Anda melintasi unit striping berurutan, Anda akan mengakses setiap disk sekali sebelum mengakses perangkat disk. Properti ini mengurangi konflik disk saat melayani permintaan besar. - Contoh kasus 1:
Jika terdapat kumpulan dari 5 disk, paritas paritas blok ke n akan disimpan pada disk (n mod 5) +1, blok ke n dari 4 disk yang lain menyimpan data yang sebenarnya dari blok tersebut. Sebuah paritas blok tidak disimpan pada disk yang sama dengan lok-blok data yang bersangkutan, karena kegagalan disk tersebut akan menyebabkan data hilang bersama dengan paritasnya dan data tersebut tidak dapat diperbaiki. Kelebihannya antara lain seperti pada level 4 ditambah lagi dengan pentebaran paritas seoerti ini dapat menghindari penggunaan berlebihan dari sebuah paritas bit seperti pada RAID level 4. kelemahannya antara lain perlunya mekanisme tambahan untuk penghitungan lokasi dari paritas sehingga akan mempengaruhi kecepatan dalam pembacaan blok maupun penulisannya. - Contoh 2: 3 unit Harddisk 300GB RAID 5 akan menghasilkan total kapasitas yang dapat
digunakan sebesar 600GB.
4 unit Harddisk 300GB RAID 5 akan menghasilkan total kapasitas yang dapat digunakan sebesar 900GB.
5 unit Harddisk 300GB RAID 5 akan menghasilkan total kapasitas yang dapat digunakan sebesar 1.2TB - Kelebihan:
- Efisiensi penggunaan kombinasi harddisk.
- Toleransi kesalahan: Jika salah satu hard disk down/error maka data tetap aman.
Kekurangan:- Kecepatan RAID 5 tidak secepat RAID 0 atau 1.
 Sumber: Referensi 2
Sumber: Referensi 2
Parity adalah kode redundansi mampu mengoreksi setiap satu, kegagalan mengidentifikasi diri. Sebagai array disk yang besar dianggap, beberapa kegagalan yang mungkin dan kode yang lebih kuat diperlukan. Selain itu, ketika sebuah disk gagal dalam array disk paritas yang dilindungi, memulihkan isi dari disk yang gagal membutuhkan berhasil membaca isi semua disk non-gagal. Probabilitas menghadapi kesalahan membaca uncorrectable selama pemulihan dapat signifikan. Dengan demikian, aplikasi dengan persyaratan keandalan yang lebih ketat membutuhkan kode koreksi kesalahan yang lebih kuat.
Setelah skema tersebut, yang disebut P + Q redundansi, menggunakan kode Reed-Solomon untuk melindungi hingga dua kegagalan disk menggunakan minimal dua disk array berlebihan. P + Q array berlebihan disk yang secara struktural sangat mirip dengan didistribusikan-paritas array disk blok-disisipkan dan beroperasi dalam banyak cara yang sama. Secara khusus, P + Q array berlebihan disk yang juga melakukan operasi write kecil menggunakan prosedur read-memodifikasi-menulis, kecuali bahwa alih-alih empat akses disk per permintaan menulis, P + Q array berlebihan disk yang memerlukan enam akses disk karena kebutuhan untuk memperbarui kedua `P 'dan Q' 'informasi. -
Kelebihan: Meskipun dua hard disk down bersamaan, data kita tetap aman.
Kekurangan:- Space total hard drive sangat berkurang karena lebih banyak dialokasikan untuk partisi redundansi.
- Kecepatan RAID 6 tidak secepat RAID 0 atau 1.
- Contoh 1: Misalnya jika sebuah harddisk mengalami kerusakan, saat proses pertukaran harddisk tersebut terjadi kerusakan lagi di salah satu harddisk yang lain, maka hal ini masih dapat ditoleransi dan tidak mengakibatkan kerusakan data di harddisk bersistem RAID 6
- Contoh 2: 4 unit Harddisk 300GB RAID 6 akan menghasilkan total kapasitas yang dapat
digunakan sebesar 600GB.
• 5 unit Harddisk 300GB RAID 6 akan menghasilkan total kapasitas yang dapat digunakan sebesar 900GB.
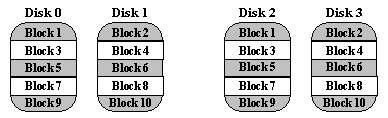
6 unit Harddisk 300GB RAID 6 akan menghasilkan total kapasitas yang dapat digunakan sebesar 1.2TB - Mirror Striped ( RAID Level 10)
RAID 10 tidak disebutkan dalam 1.988 artikel asli yang didefinisikan RAID 1 sampai RAID 5. Istilah ini sekarang digunakan untuk berarti kombinasi RAID 0 (striping) dan RAID 1 (mirroring). Disk tercermin dalam pasangan untuk redundansi dan peningkatan kinerja, maka data bergaris-garis di beberapa disk untuk kinerja maksimum. Dalam diagram di bawah, Disk 0 & 2 dan Disk 1 & 3 adalah pasangan cermin.
Jelas, RAID 10 menggunakan ruang disk lebih banyak untuk menyediakan data yang berlebihan daripada RAID 5. Namun, juga memberikan keuntungan kinerja dengan membaca dari semua disk secara paralel sementara menghilangkan hukuman menulis RAID 5. Selain itu, RAID 10 memberikan kinerja yang lebih baik daripada RAID 5 sementara drive gagal tetap unreplaced. Di bawah RAID 5, masing-masing membaca percobaan drive gagal dapat dilakukan hanya dengan membaca semua disk lainnya. Pada RAID 10, disk yang gagal dapat dipulihkan oleh membaca tunggal cermin pasangan nya. -
Keunggulan:
- Memiliki manfaat dari kecepatan dari RAID 0 dan Mirroring dari Raid 1.
- Tingkat keamanan terhadap kemungkinan hilangnya data yang lebih baik dari penggunaan sebuah harddisk.
Kelemahan:- Memiliki segala kekurangan yang dimiliki RAID 1 dan RAID 0.
 Sumber: Referensi 2
Sumber: Referensi 2
Sistem RAID Butuh Backup Tape
Perlu diingat poin penting tentang sistem RAID. Bahkan ketika Anda menggunakan skema redundansi seperti mirroring atau RAID 5 atau RAID 10, Anda masih harus melakukan backup rekaman rutin sistem anda. Ada beberapa alasan untuk bersikeras ini, di antaranya: - RAID tidak melindungi Anda dari beberapa kegagalan disk. Sementara satu disk off line untuk alasan apapun, array disk Anda tidak sepenuhnya berlebihan.
- Tape backup secara teratur memungkinkan Anda untuk pulih dari kehilangan data yang tidak berhubungan dengan kegagalan disk. Ini termasuk kesalahan manusia, kesalahan hardware, dan kesalahan perangkat lunak. Keandalan dari sistem I / O telah menjadi sama pentingnya dengan kinerja dan biaya. Ini bagian dari tutorial:
- Ulasan kehandalan dasar yang disediakan oleh berbagai disk paritas blok-interleaved
- Daftar dan membahas tiga faktor yang dapat menentukan keandalan potensi array disk.
MTTF (disk) 2 ------------------ N * (G-1) * MTTR (disk)
Disk array dengan dua disk berlebihan per kelompok paritas (misalnya: P + Q redundansi)MTTF (disk) 3 ------------------------- N * (G-1) * (G-2) * (MTTR (hard disk 2)) N - jumlah disk dalam sistem
G - jumlah disk pada kelompok paritas
Faktor yang mempengaruhi Keandalan Tiga faktor yang secara dramatis dapat mempengaruhi keandalan disk array adalah: - Crash sistem
- Uncorrectable bit-kesalahan
- Kegagalan disk berkorelasi
Crash tersebut dapat mengganggu operasi menulis, sehingga negara-negara di mana data diperbarui dan paritas tidak diperbarui atau sebaliknya. Dalam kedua kasus, paritas tidak konsisten dan tidak dapat digunakan dalam hal kegagalan disk. Teknik seperti hardware dan pasokan listrik berlebihan dapat diterapkan untuk membuat crash tersebut kurang sering.
Crash sistem dapat menyebabkan inkonsistensi paritas di kedua array disk bit-interleaved dan blok-interleaved, tapi masalahnya adalah perhatian praktis hanya dalam array disk blok-interleaved.
Sebab, tujuan kehandalan, sistem crash di array disk blok-interleaved mirip dengan kegagalan disk dalam bahwa mereka dapat mengakibatkan hilangnya paritas benar untuk garis-garis yang diubah selama kecelakaan itu.
Penafsiran kita tentang tingkat kesalahan bit uncorrectable adalah bahwa mereka mewakili tingkat di mana kesalahan yang terdeteksi selama membaca dari disk selama operasi normal dari disk drive.
Salah satu pendekatan yang dapat digunakan dengan atau tanpa redundansi adalah mencoba untuk melindungi terhadap kesalahan bit dengan memprediksi ketika disk akan gagal. VAXsimPLUS, produk dari Desember, memonitor peringatan yang dikeluarkan oleh disk dan memberitahu operator ketika merasa disk akan gagal.
Misalnya, kecelakaan mungkin tajam meningkatkan tingkat kegagalan untuk semua disk dalam array disk untuk waktu singkat. Secara umum, lonjakan daya, gangguan listrik dan hanya beralih disk dan mematikan dapat menempatkan tekanan pada komponen listrik dari semua disk yang terkena dampak. Disk juga berbagi umum hardware dukungan; ketika perangkat ini gagal, dapat menyebabkan beberapa, kegagalan disk simultan.
Disk umumnya lebih cenderung gagal baik sangat awal atau sangat terlambat dalam hidup mereka.
Kegagalan awal sering disebabkan oleh cacat sementara yang mungkin belum terdeteksi selama burn-in proses pabrikan.
Kegagalan akhir terjadi ketika disk habis dipakai. Kegagalan disk berkorelasi sangat mengurangi keandalan disk array dengan membuatnya lebih mungkin bahwa kegagalan disk awal akan diikuti oleh kegagalan disk tambahan sebelum disk gagal dapat direkonstruksi.
- kegagalan disk ganda
- sistem crash diikuti oleh kegagalan disk
- kegagalan disk diikuti oleh kesalahan bit uncorrectable selama rekonstruksi
RAID Level 5
| Kegagalan Disk ganda | |
| Sistem Crash + Disk Kegagalan | |
| Kegagalan Disk + Bit Error | |
| Software RAID | harmonik jumlah di atas |
| Hardware RAID | harmonik jumlah di atas tidak termasuk sistem crash + kegagalan disk |
P + Q disk yang Array
| Kegagalan Disk tiga | |
| Sistem Crash + Disk Kegagalan | |
| Kegagalan disk ganda + Bit error | |
| Software RAID | harmonik jumlah di atas |
| Hardware RAID | harmonik sum termasuk sistem crash + kegagalan disk |
p (disk) = Probabilitas membaca semua sektor pada disk (berasal dari ukuran disk, ukuran sektor, dan BER)
Ada tiga pertimbangan penting saat membuat pilihan untuk yang tingkat RAID yang akan digunakan untuk sistem yaitu. biaya, kinerja dan kehandalan.
Ada banyak cara yang berbeda untuk mengukur parameter ini untuk misalnya. Kinerja dapat diukur sebagai I / Os per detik per dolar, byte per detik atau waktu respon. Kita juga bisa membandingkan sistem dengan biaya yang sama, kapasitas yang sama jumlah pengguna, kinerja yang sama atau keandalan yang sama. Metode yang digunakan sangat tergantung pada aplikasi dan alasan untuk membandingkan. Misalnya, dalam aplikasi pemrosesan transaksi basis utama untuk perbandingan akan I / Os per detik per dolar sedangkan pada aplikasi ilmiah kita akan lebih tertarik pada byte per detik per dolar. Dalam beberapa sistem heterogen seperti file server baik I / O per detik dan byte per detik mungkin penting. Kadang-kadang penting untuk mempertimbangkan keandalan sebagai dasar untuk perbandingan.
Mengambil melihat lebih dekat pada tingkat RAID kita amati bahwa sebagian besar tingkat yang mirip satu sama lain. RAID level 1 dan RAID level 3 array disk dapat dilihat sebagai subclass dari tingkat RAID 5 array disk. Juga RAID tingkat 2 dan RAID tingkat 4 array disk umumnya ditemukan akan kalah dengan RAID level 5 array disk. Oleh karena itu masalah memilih di antara tingkat RAID 1 sampai 5 adalah bagian dari masalah yang lebih umum memilih ukuran kelompok paritas yang sesuai dan Unit striping untuk tingkat RAID 5 array disk.
Beberapa Perbandingan
Diberikan di bawah ini adalah tabel yang membandingkan throughput berbagai skema redundansi untuk empat jenis I / O permintaan. I / O permintaan pada dasarnya membaca dan menulis yang dibagi menjadi kecil (membaca & menulis) dan yang besar. Mengingat fakta bahwa data kami telah tersebar di beberapa disk (data striping), kecil mengacu pada permintaan I / O dari satu unit striping sementara permintaan I / O besar mengacu pada permintaan dari satu garis penuh (satu unit garis dari masing-masing disk dalam kelompok koreksi kesalahan).
Tabel di atas tabulates throughput maksimum per dolar relatif tingkat 0 untuk tingkat RAID 0, 1, 3, 5 dan 6. Untuk tujuan praktis kita mempertimbangkan tingkat RAID 2 & 4 kalah dengan RAID level 5 array disk, sehingga kita tidak menunjukkan perbandingan. Biaya sistem berbanding lurus dengan jumlah disk menggunakan dalam array disk. Dengan demikian tabel menunjukkan kepada kita bahwa diberikan tingkat RAID biaya setara 0 dan RAID level 1 sistem, tingkat RAID 1 sistem dapat mempertahankan setengah jumlah menulis kecil per detik bahwa RAID tingkat 0 sistem dapat mempertahankan. Ekuivalen biaya kecil menulis dua kali lebih mahal di tingkat RAID 1 sistem seperti pada tingkat RAID 0 sistem.
Tabel tersebut juga menunjukkan efisiensi penyimpanan setiap tingkat RAID. Efisiensi penyimpanan adalah sekitar terbalik biaya dari setiap unit kapasitas pengguna relatif terhadap tingkat RAID 0 sistem. The efisiensi penyimpanan sama dengan metrik kinerja / biaya untuk menulis besar.
Sumber: Referensi 1 Angka-angka di atas grafik metrik kinerja / biaya dari tabel di atas untuk tingkat RAID 1, 3, 5 dan 6 pada rentang ukuran kelompok paritas. Kinerja / biaya tingkat RAID 1 sistem setara dengan kinerja / biaya tingkat RAID 5 sistem ketika ukuran kelompok paritas sama dengan 2. Kinerja / biaya tingkat RAID 3 sistem selalu kurang dari atau sama dengan kinerja / biaya tingkat RAID 5 sistem. Hal ini diharapkan mengingat bahwa RAID tingkat 3 sistem adalah subclass dari tingkat RAID 5 sistem diturunkan dengan membatasi ukuran unit striping sehingga semua permintaan akses persis garis paritas data. Karena konfigurasi RAID tingkat 5 sistem tidak dikenakan pembatasan tersebut, kinerja / biaya tingkat RAID 5 sistem tidak pernah bisa kurang dari itu sistem RAID tingkat setara 3. Tentu saja generalisasi seperti khusus untuk model array disk yang digunakan dalam percobaan di atas. Pada kenyataannya, implementasi khusus dari RAID level 3 sistem dapat memiliki kinerja / biaya yang lebih baik daripada implementasi khusus dari sistem tingkat RAID 5.
Pertanyaan yang tingkat RAID untuk menggunakan lebih baik dinyatakan sebagai pertanyaan konfigurasi yang lebih umum mengenai ukuran kelompok paritas dan striping satuan. Untuk ukuran kelompok paritas 2, mirroring yang diinginkan, sedangkan untuk yang sangat kecil satuan striping RAID level 3 akan cocok.
Gambar di bawah ini plot metrik kinerja / biaya dari tabel di atas untuk tingkat RAID 3, 5 & 6.
RAID Z
Raid Z dan RAID Z2 adalah penemuan Sun Micro System. RAID Z memiliki semua manfaat dari RAID 5 dan fitur lainnya yang membuatnya jauh lebih unggul. Seperti dengan RAID 5, RAID Z dapat mendukung
sejumlah hard disk yang bekerja sama dan satu disk untuk redudansi. Jumlah minimum dari hard disk adalah tiga dan hanya satu yang bisa down pada suatu waktu. Jika lebih dari satu hard disk rusak pada saat yang sama, maka kita beresiko kehilangan data.
Kelebihan: Memiliki semua kelebihan dari RAID 5 dan fitur lainnya.
Kelemahan: Hanya dapat digunakan dengan OS berbasis Open Solaris seperti Nexenta dan atau sistem berbasis BSD seperti FreeBSD.
Kapan menggunakan: RAID Z adalah level RAID terbaik untuk penyimpanan/storage. Pada dasarnya RAID Z melengkapi hampir semua kekurangan dari RAID tingkat sebelumnya dan menambahkan banyak fitur
baru. Namun hanya bisa digunakan dengan sistem berbasis Solaris dan BSD. RAID Z sangat baik untuk digunakan dalam NAS / lainnya untuk penyimpanan data berskala besar.
RAID Z2
Raid Z2 hampir identik dengan Raid Z dan mirip dengan RAID 6. Dalam RAID Z2, meski dua hard disk bisa down di waktu bersamaan namun data akan tetap aman dan mudah diakses. Sama seperti RAID Z,
RAID Z2 jauh lebih unggul dengan RAID 6 karena di dalamnya terdapat banyak fitur lainnya. Jumlah minimum drive untuk menggunakan RAID Z2 adalah empat.
Keuntungan: Data lebih aman meski dua drive bisa down pada saat yang sama bukan hanya satu. Memiliki semua manfaat dari RAID Z.
Kekurangan: Dua hard disk digunakan untuk paritas, sehingga ukuran jumlah gabungan space sangat terbatas. Hanya dapat digunakan dengan OS berbasis Open Solaris seperti Nexenta dan atau sistem berbasis BSD seperti FreeBSD.
Kapan menggunakan:Sama seperti RAID Z tetapi dilengkapi dengan tambahan tingkat keamanan. Tidak untuk digunakan jika butuh space yang besar.
RAID Level 0 +1: Sebuah Cermin Stripes bukan merupakan tingkat RAID asli, tetapi merupakan gabungan dua RAID yaitu RAID 0 stripes yang diciptakan, dan RAID 1 mirror. Digunakan pada data replikasi dan sharing antar disk.
RAID Level 10: Sebuah Stripe of Mirrors
Tak satu pun dari tingkat RAID asli, beberapa mirror RAID 1 diciptakan, dan RAID 0 stripe dibuat pada tingkatan ini. RAID 10 diklasifikasikan sebagai controller RAID futuristik dengan Kehandalan tinggi dan kinerja sangat tertanam dalam RAID controller tunggal. Persyaratan minimum untuk membentuk tingkat RAID 10 controller 4 data disk. Pelaksanaan RAID 10 didasarkan pada bergaris array RAID 1 segmen array, dengan hampir tingkat toleransi kesalahan yang sama seperti RAID 1. RAID 10 array controller dan cocok untuk tanpa kompromi ketersediaan dan throughput tinggi sangat diperlukan sistem dan lingkungan.
RAID Level 7
Sebuah merek dagang Penyimpanan Computer Corporation yang menambahkan caching untuk Tingkat 3 atau 4. RAID7 membuat sistem operasi sebagai controller, caching menggunakan jalur cepat. RAID 7 adalah array asynchrony Dioptimalkan untuk tinggi saya / kecepatan transfer data dan O dianggap sebagai RAID controller dikelola paling tersedia. Menulis kinerja keseluruhan juga dikenal menjadi 50% sampai 90% lebih baik dan diperbaiki dibandingkan array tingkat poros tunggal tanpa transferensi data tambahan yang diperlukan untuk penanganan paritas.
RAID 0 +3
RAID level 0 3 atau RAID tingkat 03 adalah array paritas khusus di disk bergaris. Setiap blok data di tingkat 3 RAID ini dipecah antara RAID 0 array mana potongan-potongan yang lebih kecil bergaris di seluruh disk.
RAID 30
RAID level 30 juga dikenal sebagai striping array paritas khusus. Ini adalah kombinasi dari RAID level 3 dan tingkat RAID 0. RAID 30 memberikan kecepatan transfer data yang tinggi, dikombinasikan dengan keandalan data yang tinggi. RAID 30 adalah paling baik dilaksanakan pada dua array disk RAID 3 dengan data garis-garis di kedua array disk. RAID 30 memecah data ke dalam blok yang lebih kecil, dan kemudian garis-garis blok data untuk setiap set 3 raid RAID. RAID 3 memecah data ke dalam blok-blok yang lebih kecil, menghitung paritas dengan melakukan ATAU Eksklusif di blok, dan kemudian menulis blok untuk semua kecuali satu drive dalam array. Bit paritas dibuat menggunakan OR eksklusif kemudian ditulis ke drive terakhir dalam tiap array RAID 3. Ukuran setiap blok ditentukan oleh parameter ukuran jalur, yang mengatur kapan RAID dibuat.
Satu drive dari masing-masing yang mendasari RAID 3 set bisa gagal. Sampai drive gagal diganti drive lain dalam set yang mengalami seperti kegagalan adalah satu titik kegagalan untuk seluruh RAID 30 array. Dengan kata lain, jika salah satu drive gagal, semua data disimpan di seluruh array hilang. Waktu yang dihabiskan dalam pemulihan (mendeteksi dan menanggapi kegagalan drive, dan membangun kembali proses ke drive baru terpasang) merupakan periode kerentanan terhadap set RAID.
Sebuah RAID 50 menggabungkan lurus blok -tingkat striping RAID 0 dengan paritas terdistribusi RAID 5. Ini adalah RAID 0 array bergaris di RAID 5 elemen. Hal ini membutuhkan setidaknya 6 drive. Berikut adalah contoh di mana tiga koleksi 240 GB RAID 5s bergaris sama untuk membuat 720 GB ruang penyimpanan total:
Satu drive dari masing-masing 5 set RAID bisa gagal tanpa kehilangan data. Namun, jika drive gagal tidak diganti, drive yang tersisa dalam set kemudian menjadi satu titik kegagalan untuk seluruh array. Jika salah satu drive yang gagal, semua data disimpan di seluruh array hilang. Waktu yang dihabiskan dalam pemulihan (mendeteksi dan menanggapi kegagalan drive, dan membangun kembali proses ke drive baru terpasang) merupakan periode kerentanan terhadap set RAID.
RAID 51
Sebuah RAID51 atau RAID5 +1 adalah sebuah array yang terdiri dari dua RAID 5 yang merupakan cermin satu sama lain. Umumnya konfigurasi ini digunakan supaya setiap RAID5 berada pada controller yang terpisah. Dalam konfigurasi ini membaca dan menulis yang seimbang di kedua RAID5s. Beberapa controller mendukung RAID51 di beberapa saluran dan kartu dengan mengisyaratkan untuk menjaga irisan yang berbeda disinkronisasi. Namun suatu RAID51 juga dapat dilakukan dengan menggunakan teknik RAID berlapis. Dalam konfigurasi ini, kedua RAID5 itu tidak tahu bahwa mereka adalah cermin dari satu sama lain dan RAID1 tidak tahu bahwa disk yang mendasarinya adalah RAID5’s. Konfigurasi ini dapat mempertahankan dua kegagalan disk (satu per array) sebelum data akan hilang. Jumlah maksimum ruang dari RAID51 adalah (N) dimana N adalah ukuran dari RAID5 individu
Sebuah RAID 60 menggabungkan striping blok-tingkat lurus RAID 0 dengan paritas ganda terdistribusi RAID 6. Artinya, RAID 0 array bergaris di RAID 6 elemen. Hal ini membutuhkan setidaknya 8 disk. Berikut adalah contoh di mana dua kumpulan RAID 6s 240 GB yang bergaris sama untuk membuat 480 GB ruang penyimpanan total:
Karena didasarkan pada RAID 6, dua disk dari masing-masing 6 set RAID bisa gagal tanpa kehilangan data. Juga kegagalan sementara satu disk adalah membangun kembali dalam satu RAID 6 tetapkan tidak akan mengakibatkan hilangnya data. RAID 60 telah meningkatkan toleransi kesalahan, setiap dua drive bisa gagal tanpa kehilangan data dan sampai empat total selama itu hanya dua dari masing-masing sub-array RAID6. Striping membantu meningkatkan kapasitas dan kinerja tanpa menambahkan disk untuk setiap set 6 RAID (yang akan menurunkan ketersediaan data dan dapat mempengaruhi kinerja). RAID 60 meningkatkan atas kinerja RAID 6. Terlepas dari kenyataan bahwa RAID 60 sedikit lebih lambat dari RAID 50 dalam hal menulis karena overhead ditambahkan perhitungan paritas lebih, ketika data keamanan yang bersangkutan ini penurunan kinerja mungkin dapat diabaikan.
RAID S
Juga disebut Paritas RAID, stripe yang dimiliki oleh sistem RAID paritas EMC Corporation digunakan dalam sistem penyimpanan Symmetrix nya
pengertian Istilah penting Dalam Raid yaitu:
* Data Striping: sebuah metoda untuk menyatukan beberapa harddisk untuk menjadi sebuah harddisk virtual. Striping pada dasarnya membuat partisi pada setiap harddisk menjadi banyak stripe (potongan kecil) yang mulai dari 512byte atau beberapa megabyte. Masing-masing stripe ini akan di tumpuk satu sama lain secara berputar / bergilir antar harddisk, oleh karena itu gabungan tempat penyimpanan di harddisk akan berurutan (berselang seling) dalam bentuk stripe dari setiap harddisk. Tergantung pada kebutuhan aplikasi, I/O atau data intensif, akan menentukan besar atau kecil-nya stripe yang akan digunakan.
* Redudansi adalah kejadian berulangnya data atau kumpulan data yang sama dalam sebuah database yang mengakibatkan pemborosan media penyimpanan
* Mirroring (penyalinan data ke lebih dari satu buah hard disk),
Striping (pemecahan data ke beberapa hard disk) dan juga koreksi kesalahan, di mana redundansi data disimpan untuk mengizinkan kesalahan dan masalah untuk dapat dideteksi dan mungkin dikoreksi (lebih umum disebut sebagai teknik fault tolerance/toleransi kesalahan)
* code hamming atau kode hamming: sistem pengkoreksian kesalahan kode Hamming. Yang ditemukan oleh Prof. Wesley Richard Hamming di laboratorium bell dengan menggunakan diagram Venn.
Dengan tiga buah lingkaran, yang berpotongan, terdapat tujuh kompartemen. Kita akan memberikan 4 buah bit data ke kompartemen yang terletak di tengah (Gambar 2a). kompartemen sisanya diisi dengan apa yang kita sebut bit paritas. Setiap bit paritas dipilih sehingga bilangan 1 dalam lingkaran berjumlah genap (Gambar 2b). Jadi, karena lingkaran A terdiri dari tiga buah bilangan 1, maka bit paritas dalam lingkaran itu disetel menjadi 1. sekarang, apabila suatu error mengubah salah satu bit data (Gambar 2c), maka error itu akan dengan mudah ditemukan.
Dengan
memeriksa bit paritas, cacat-cacat dapat ditemukan pada lingkaran A dan C namun
tidak pada lingkaran B. hanya salah satu dari kompartemen berada pada A dan C
namun tidak pada B. karena itu error dapat dikoreksi dengan mengubah bit
tersebut. Untuk menjelaskan kosep tersebut, kita akan membuat kode yang dapat
mendeteksi dan mengoreksi error bit tunggal di dalam word 8 bit
Untuk
memulainya, kita tentukan panjang kode seharusnya. Sehubungan dengan
gambar 1, logika perbandingan menerimanya sebagai input dua nillai K-Bit.
Perbandingan bit demi bit dilakukan dengan memperhatikan exclusive-or
kedua input itu. Hasilnya disebut sebagai sindrom word. Jadi sindrom
adalah 0 atau 1apabila terdapat atau tidak cocok data posisi bit kedua input
tersebut.
Dengan
demikian sindron word mempunyai lebar K dan memiliki range 2 yang
berada diantara 0 dan 2-1. Nilai
0 berarti bahwa tidak terdeteksi error, yang menyisakan 2– 1 buah
nilai untuk mengindikasikan bit mana yang mengalami error, bila terdapat error.
Sekarang, karena suatu error terjadi pada sembarang M bit data atau K bit
check, maka kita harus memiliki. 2-1 > M
+ K.
Persamaan
ini memberikan jumlah bit yang diperlukan untuk mengoreksi error bit tunggal
didalam sebuah word yang berisi M buah bit data. Pada table 1 merupakan daftar
bit-bit cek yang diperlukan untuk bermacam-macam panjang word data.
Pengkoreksian,
Kesalahan tunggal
|
Pengkoreksian Kesalahan tunggal Pendeteksian
kesalahan ganda
|
|||
Bit-bit
Data
|
Bit-bit
Cek
|
%Peningkatan
|
Bit-bit
Cek
|
%Peningkatan
|
8
16
32
64
128
256
|
4
5
6
7
8
9
|
50
31,25
18,75
10,94
6,25
3,25
|
5
6
7
8
9
10
|
62,5
37,5
21,875
12,5
7,03
3,91
|
Tabel
1. Kenaikan panjang
word dengan koreksi kesalahan
Posisi bit
|
Nomor
|
Bit cek
|
Bit Data
|
12
11
10
9
8
7
6
5
4
3
2
1
|
1100
1011
1010
1001
0111
0110
0101
0100
0011
0010
0001
|
C8
C4
C2
C1
|
M8
M7
M6
M5
M4
M3
M2
M1
|
Gambar 3.
Layout Bit-bit data dan Bit-bit cek
Dari table,
kita akan ketahui bahwa suatu word 8 bit data memerlukan 4 bit chek.
Untuk mudahnya kita akan menurunkan sindrom 4 bit dengan memakai karakteristik
berikut ini :
· Jika sindrom semuanya berisi
0, maka tidak terdapat error.
· Jika sindrom berisi sebuah dan
hanya sebuah bityang disetel ke 1, makatelah terjadi suatu error pada salah
satu dari 4 buah bit check.
· Jika sindrom berisi lebih dari
sebuah bit disetel ke 1, maka nilai numeric sindrom mengindikasikan posisi bit
data yang mengalami error. Bit data ini diinversikan untuk
keperluan koreksi.
C1 =
M1 M2
M4 M5 M7
C2 =
M1
M3 M4
M6 M7
C4 =
M2
M3 M4 M8
C8 =
M5
M6 M7 M8
* Code Reed Solomon: algoritma Reed-Solomon secara luas digunakan dalam telekomunikasi dan penyimpanan data. Ini adalah bagian dari semua CD dan DVD pembaca, RAID 6 implementasi, dan bahkan sebagian besar barcode, di mana ia memberikan koreksi kesalahan dan pemulihan data. Hal ini juga melindungi data telemetri yang dikirim oleh deep-space probe seperti Voyagers I dan II. Dan itu digunakan oleh ADSL dan DTV hardware untuk memastikan data kesetiaan selama transmisi dan penerimaan. Algoritma ini merupakan gagasan dari Irving Reed dan Gustave Solomon, keduanya insinyur di MIT Lincoln Labs. Pengenalan publik adalah melalui 1960 kertas "Kode Polinomial Tertentu Hingga Fields." Yang cukup menarik, kertas yang tidak memberikan cara yang efisien untuk memecahkan kode kesalahan disajikan. Sebuah skema decoding yang lebih baik dikembangkan pada tahun 1969 oleh Elwyn Berklekamp dan James Massey.
Materi Arsitektur Komputer terlengkap, dapat dijumpai disini http://mycomputerarchitecture.blogspot.co.id/
BalasHapus